How does a Gamma Camera work? Specifically, how do they get high resolution pictures out of a small array of photomultipler tubes?
Low-energy gamma-ray imaging is very awkward and primitive in many respects. Above an energy of about 10 keV, it is not possible to make focusing optics based on lenses or mirrors, and direct imaging is not practical. Then more complicated and cumbersome methods have to be employed, and a computer is required to reconstruct the image. Between about 10 keV and 1-2 MeV, imaging is usually done with any of several possible extensions of the pinhole camera, which are used in medicine and in gamma-ray astronomy. In medicine, such devices are often called gamma cameras; in astronomy, they are usually called coded-aperture instruments.
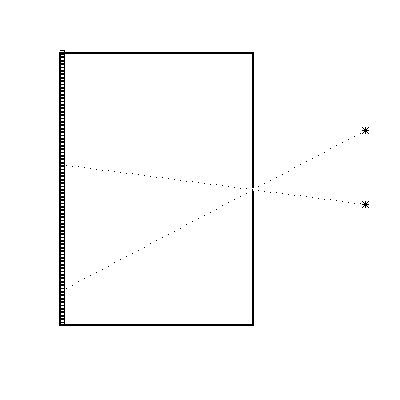
Recall how for a pinhole camera an opaque screen with a small hole casts an inverted image on the opposite wall of the box. Figure 1 shows gamma rays entering from the right, to strike the detectors on the surface at the left. No lenses are required, although the box must be opaque -- not entirely easy at, say, 511 keV. Notice that if there are multiple sources (let us say stars) on the right, each will cast its own image (really just a shadowgram) at a unique point on the right. Thus the device actually creates an inverted image. The imaging surface could be photographic film, but this is too insensitive and non-linear for astronomical or medical use, so the little boxes in the image plane represent some kind of position- sensitive gamma-ray detector, such as an array of scintillation counters, each with its own PMT.
So far, so good. There is a very serious problem, however. For a sharp image, we obviously need to make the hole as small as possible. Unfortunately, this makes the image extremely dim, in proportion to the area of the hole. (Normal cameras have it both ways by using a lens, which lets through lots of light, without the blur of a big hole.) If you want to take a picture of a nuclear bomb exploding, you can probably stop here; but for other purposes some method must be found to get more photons through the system.
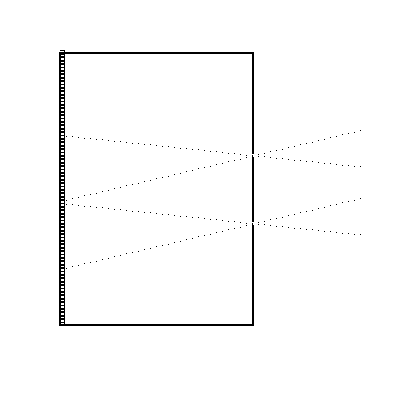
Evidently you could double the amount of light by cutting a second hole (Figure 2) in the aperture screen, but at a serious price: stars in the image plane would appear double (separated, we should notice, by a characteristic fixed interval), and images of complex objects would seem to be quite confused. With more holes, things would get even worse. At first this seems an unpromising approach! However (in an early form of coded aperture proposed by R. H. Dicke in 1967), suppose we make the "opaque" screen (the coded aperture, or mask) a large array of random pinholes, so that each position has a 50% chance of being open or blocked. Now the image is really a mess (I won't even try to draw a picture), although there is plenty of light. But look: if we make an identical copy of the mask (the decoder), and slide it around over the image plane, a very interesting and wonderful thing happens. If the decoder is accidentally in a position such that a star shining through a hole in the mask on the right happens to shine on through the same hole in the decoder on the left, then every hole in the mask will align properly for its corresponding hole in the decoder, but only for that one star.
Thus for that star, all the light hitting a hole on the right would get through to a detector on the left; but only for the one unique position of the second, decoding, mask. At other positions, about 50% of the light striking the decoder would still get through by chance, since light from a pinhole in the mask would have a 50/50 chance of encountering an open pinhole on the left. If we are looking at a field of many stars, we would find that as we slide the decoder around, at most positions about 25% of the total light (50% through the mask on the right, and then 50% again through the decoder on the left) gets through. However, at certain positions, the transmitted light suddenly jumps, as one particular star or another lines up just right and its transmission jumps to 50%. So those positions of the decoder in effect tell us the positions of the stars. Thus we could, by sliding the decoder about and measuring the transmitted light, map out the position and intensity of all the stars in the field of view. For a continuous image, as in medicine, we would measure the transmitted light at each position of the decoder to get the intensity at the corresponding point in the image.
If we actually used a sliding mask on the left, mapping the image would be a terribly slow process! At each position we would have to count photons long enough to distinguish the 50% of the star signal, over the background due to 25% of all the other stars. However, if we use a position-sensitive detector, such as an array of phototubes each with its own scintillator, we can do the masking in a computer, by adding up only the detectors under the holes of the decoder. This is a crucial advantage, because it means that all the detectors can be open all the time, and the entire process of measuring at each position can happen in parallel. Mathematically, if we think of the mask as a function m(x, y) of position x and y, which is either 1 or 0 at random, then this operation of sliding the decoder and then summing the product of the two functions is called forming the cross correlation of the two; since we are actually cross-correlating the mask m with itself, it is called the auto-correlation. Considered as a function of the shift, the random pinhole mask has an auto-correlation function which is 0.5 at zero shift, and approximately 0.25 for all others.
So to decode the image, we take the count data n from the detector at a pixel with detector co-ordinates (x', y'), multiply by the decoder m(x'-x, y'-y) shifted by (x'-x, y'-y), multiply by the mask m(x, y), forming:
and then sum S formed in this way over pixels (x', y'), to obtain the image I(x, y). This kind of auto-correlation operation is something that computers can perform very quickly.
Many variations on this theme exist. The random pinhole mask described above is easy to understand, but somewhat better choices (and a considerable mathematical theory) exist. In particular, the random pinhole mask has an autocorrelation function which is only approximately constant (about 0.25) for non-zero shifts, because it depends on the exact number of holes that happen to line up, and that is random. Using the theory of Cyclic Difference Sets, it is possible to design masks which have a truly constant auto-correlation function for non-zero shifts. Since any bumpiness in the auto-correlation function contributes noise to the image, such masks can be used to make more sensitive coded aperture instruments; but the principle for all is very similar.
Reference:
Baumert, L. D., "Cyclic Difference Sets", (New York: Springer Verlag) 1971.
{kind=link}
{kind=link}